Install Cloudera Manager from an AWS instance
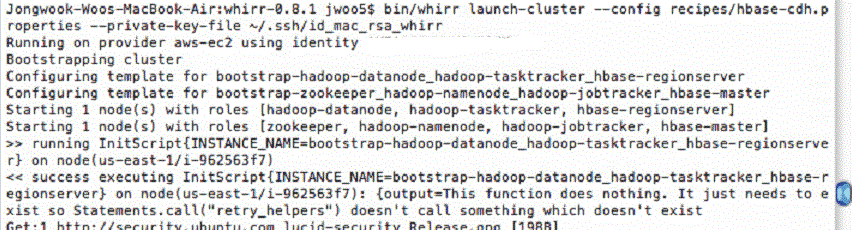
You can launch an AWS instance at CentOS 6.3 and ssh to the instance. Then, download the Cloudera Manager 4.5 installer and execute it on the remote instance:
$ wget http://archive.cloudera.com/cm4/installer/latest/cloudera-manager-installer.bin
$ chmod +x cloudera-manager-installer.bin
$ sudo ./cloudera-manager-installer.bin
(1) Follow the command based installation accepting licenses.
(2) Open and go to Cloudera Manager's Web UI, which might be local URLbut you may use the global URL, to launch the services.
(3) All Services > Add Cluster > Continue on Coudera Manager Express Wizard > CentOS 6.3; m1.xlarge; ...
Note: >= m1.large recommended
Stop unneccessay services
Stop HBase, Hive, Oozie, Sqoop
All systems are located at 'usr/lib/'
For example, /usr/lib/solr, /usr/lib/zookeeper, ...
Optional: Activate Solr service
After launching Cloudera Manager and its instances as shown at whirr_cm above, go to 'Host' > 'Parcels' tab of the Cloudera Manager's Web UI. Then, you can download the latest available CDH, Solr, Impala.
Download "SOLR 0.9.1-1.cdh4.3.0.p0.275" > Distribute > Activate > Restart the current Cluster
Optional: download CDH 4.3.0-1
Download "CDH 4.3.0-1.cdh4.3.0.p0.22" > Distribute > Activate > Restart the current Cluster
Note: Restarting the cluster will take several minutes
Add Solr service
Actions (of Cluster 1 - CDH4) > Add a Service > Solr > Zookeeper as a dependency
Open a Web UI of Hue
Default login/pwd is admin You can see Solr. Select it
Update Solr conf at a zookeeper node
You can see a solr configuration file as '/etc/default/solr' and update it with as follows:
sudo vi /etc/default/solr
Note: it may not recognize 'localhost' so that use '127.0.0.1' alternatively
Create the /solr directory in HDFS:
$ sudo -u hdfs hadoop fs -mkdir /solr
$ sudo -u hdfs hadoop fs -chown solr /solr
Create a collection
You change to root account and need to add solr to zookeeper. From now on, I run shell commands as root user.
$ sudo su
$ solrctl init
or
$ solrctl init --force
Then, at Cloudera Manager's Web UI, restart solr service.
Run the following commands to create a collection at a zookeeper node
$ solrctl instancedir --generate $HOME/solr_configs
$ solrctl instancedir --create collection $HOME/solr_configs
$ solrctl collection --create collection -s 1
While running 'solrctl collection ...', you may go to /var/log/solr and check out if the solr runs well without any error:
$ tail -f solr-cmf-solr1-SOLR_SERVER-ip-10-138-xx-xx.ec2.internal.log.out
Upload an example data to solr
$ cd /usr/share/doc/solr-doc-4.3.0+52/example/exampledocs/
$ java -Durl=http://127.0.0.1:8983/solr/collection/update -jar post.jar *.xml
SimplePostTool version 1.5
Posting files to base url http://127.0.0.1:8983/solr/collection/update using content-type application/xml..
POSTing file gb18030-example.xml
POSTing file hd.xml
POSTing file ipod_other.xml
...
POSTing file utf8-example.xml
POSTing file vidcard.xml
14 files indexed.
COMMITting Solr index changes to http://127.0.0.1:8983/solr/collection/update..
Time spent: 0:00:00.818
Query using Hue Web UI
Open Hue Web UI at Cloudera Manager's Hue service and select solr tab.
1. Make sure to import collections - core may not be needed.
2. select "Search page" link at the top right of the solr web UI page.
3. As default, the page shows 1-15 of 32 results.
4. Type in 'photo' at a search box ans will show 1 -2 of 2 results.
Customize the view of Solr Web UI
Select 'Customize this collection' that will present Visual Editor for view.
Note: you can see the same content from https://github.com/hipic/cdh-solr