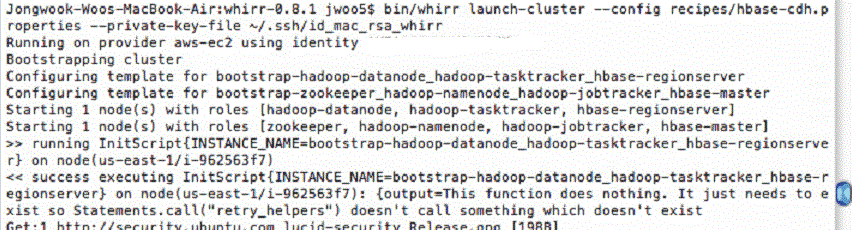
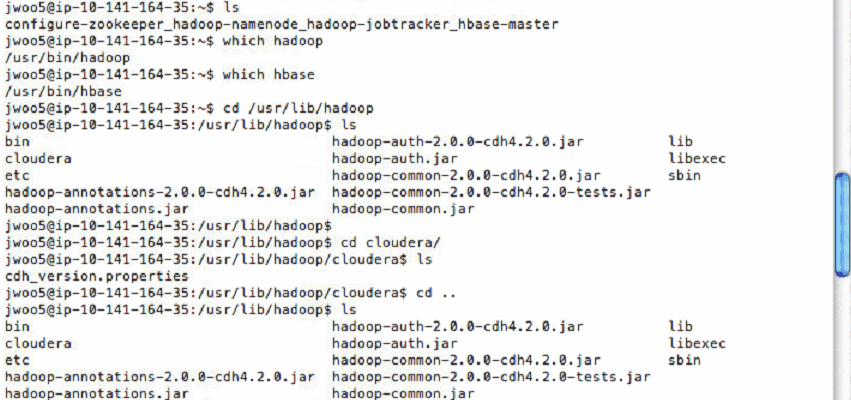
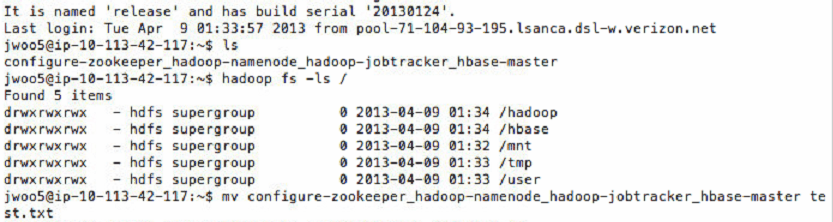
It is not easy to set up both Hadoop and HBase on EC2 at the same time. This is to illustrate how to set them up together with Apache Incubator project Whirr. Besides, it describes how to login the master node so that you can easily execute your Hadoop codes and HBase data on thde node remotely.
References
[1] Phil Whelan, http://www.philwhln.com/run-the-latest-whirr-and-deploy-hbase-in-minutes
[2] http://incubator.apache.org/whirr/quick-start-guide.html
[3] http://incubator.apache.org/whirr/whirr-in-5-minutes.html
[4] http://stackoverflow.com/questions/5113217/installing-hbase-hadoop-on-ec2-cluster
[5] http://www.philwhln.com/map-reduce-with-ruby-using-hadoop
[5.1] http://www.cloudera.com/blog/2011/01/map-reduce-with-ruby-using-apache-hadoop/
********************** Install Hadoop/HBase on Whirr [1] on Ubuntu 10.04 **********************
NOTES: install JDK 1.6 not JRE
1) mvn clean install
First time: hbsql not found install error
Second time: no problem successful
2) set the following:
export AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxxxxxxxxxx
export AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
2.a) 5 min test of Whirr [3]
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa_whirr
bin/whirr launch-cluster --config recipes/zookeeper-ec2.properties --private-key-file ~/.ssh/id_rsa_whirr
echo "ruok" | nc $(awk '{print $3}' ~/.whirr/zookeeper/instances | head -1) 2181; echo
2.b) bin/whirr destroy-cluster --config recipes/zookeeper-ec2.properties
3)jongwook@localhost:~/whirr$ bin/whirr launch-cluster --config hbase-ec2.properties
3.a) Exception in thread "main" org.apache.commons.configuration.ConfigurationException: Invalid key pair: (/home/jongwook/.ssh/id_rsa, /home/jongwook/.ssh/id_rsa.pub)
Solution)
ssh-keygen -t rsa -P ''
4) You will see the following for about 5 min
<< (ubuntu@184.72.173.143:22) error acquiring Session(ubuntu@184.72.173.143:22): Session.connect: java.io.IOException: End of IO Stream Read
<< bad status -1 ExecResponse(ubuntu@50.17.19.46:22)[./setup-jongwook status]
<< bad status -1 ExecResponse(ubuntu@174.129.131.50:22)[./setup-jongwook status]
5) then, hbase folder with shell and xml files are generated under '.whirr'
jongwook@localhost:~/whirr$ ls -al /home/jongwook/.whirr/
total 12
drwxr-xr-x 3 jongwook jongwook 4096 2011-06-17 16:19 .
drwxr-xr-x 46 jongwook jongwook 4096 2011-06-17 16:09 ..
drwxr-xr-x 2 jongwook jongwook 4096 2011-06-17 16:19 hbase
6) Setup proxy server at Systems > Preferences > Network Proxy [5, 5.1]
Mark SOCKS Proxy
Proxy Server: localhost
port: 6666
6.a) at another terminal - temr2, setupHadoopEnv :
jongwook@localhost:~/whirr$ source ~/Documents/setupHadoop0.20.2.sh
6.b) And, at another terminal - temr2, Run Hadoop proxy to connect external and internal clusters
jongwook@localhost:~/whirr$ sh ~/.whirr/hbase/hadoop-proxy.sh
Running proxy to Hadoop cluster at ec2-184-xx-xxx-0.compute-1.amazonaws.com. Use Ctrl-c to quit.
Warning: Permanently added 'ec2-184-xx-xxx-0.compute-1.amazonaws.com,184.72.152.0' (RSA) to the list of known hosts.
7) Run a sample hadoop shell at the original terminal - term1
11/06/17 17:03:20 WARN conf.Configuration: DEPRECATED: hadoop-site.xml found in the classpath. Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, mapred-site.xml and hdfs-site.xml to override properties of core-default.xml, mapred-default.xml and hdfs-default.xml respectively
Found 4 items
drwxr-xr-x - hadoop supergroup 0 2011-06-17 16:19 /hadoop
drwxr-xr-x - hadoop supergroup 0 2011-06-17 16:19 /hbase
drwxrwxrwx - hadoop supergroup 0 2011-06-17 16:18 /tmp
drwxrwxrwx - hadoop supergroup 0 2011-06-17 16:18 /user
8) at another terminal - temr3, setupHadoopEnv :
jongwook@localhost:~/whirr$ source ~/Documents/setupHadoop0.20.2.sh
8.a) And, at another terminal - temr3, Run HBase proxy to connect external and internal clusters; NOTE: need to close Hadoop proxy server because the port 6666 is shared
jongwook@localhost:~/whirr$ sh ~/.whirr/hbase/hbase-proxy.sh
Running proxy to HBase cluster at ec2-184-72-152-0.compute-1.amazonaws.com. Use Ctrl-c to quit.
Warning: Permanently added 'ec2-184-72-152-0.compute-1.amazonaws.com,184.xx.xxx.0' (RSA) to the list of known hosts.
9) Log in the master to run hadoop code with hbase data; user name is your local login, eg, jongwook for me.
jongwook@localhost:~/whirr$ ssh -i /home/jongwook/.ssh/id_rsa jongwook@ec2-75-xx-xx-xx.compute-1.amazonaws.com
OR
jongwook@localhost:~/whirr$ ssh -i /home/jongwook/.ec2/id_rsa-dal_keypair jongwook@ec2-75-xx-xx-x.compute-1.amazonaws.com
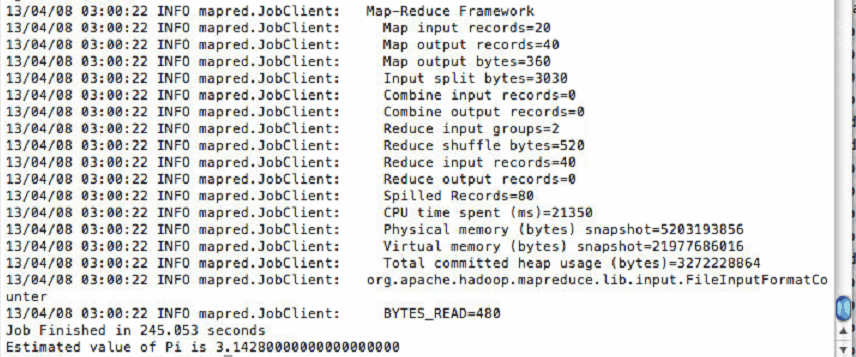
10) Now run Hadoop pi demo:
[root@ip-10-116-94-104 ~]# cd /usr/local/hadoop-0.20.2/
[root@ip-10-116-94-104 hadoop-0.20.2]# bin/hadoop jar hadoop-0.20.2-examples.jar pi 20 1000
11) setup path and CLASSPATH to run hbase and hadoop codes
export HADOOP_HOME=/usr/local/hadoop-0.20.2
export HBASE_HOME=/usr/local/hbase-0.89.20100924
export PATH=$HADOOP_HOME/bin:$HBASE_HOME/bin:$PATH
# CLASSPATH for HADOOP
export CLASSPATH=$HADOOP_HOME/hadoop-0.20.2-core.jar:$HADOOP_HOME/hadoop-0.20.2-ant.jar:$CLASSPATH
export CLASSPATH=$HADOOP_HOME/hadoop-0.20.2-examples.jar:$HADOOP_HOME/hadoop-0.20.2-test.jar:$CLASSPATH
export CLASSPATH=$HADOOP_HOME/hadoop-0.20.2-tools.jar:$CLASSPATH
#export CLASSPATH=$HADOOP_HOME/commons-logging-1.0.4.jar:$HADOOP_HOME/commons-logging-api-1.0.4.jar:$CLASSPATH
# CLASSPATH for HBASE
export CLASSPATH=$HBASE_HOME/hbase-0.89.20100924.jar:$HBASE_HOME/lib/zookeeper-3.3.1.jar:$CLASSPATH
export CLASSPATH=$HBASE_HOME/lib/commons-logging-1.1.1.jar:$HBASE_HOME/lib/avro-1.3.2.jar:$CLASSPATH
export CLASSPATH=$HBASE_HOME/lib/log4j-1.2.15.jar:$HBASE_HOME/lib/commons-cli-1.2.jar:$CLASSPATH
export CLASSPATH=$HBASE_HOME/lib/jackson-core-asl-1.5.2.jar:$HBASE_HOME/lib/jackson-mapper-asl-1.5.2.jar:$CLASSPATH
export CLASSPATH=$HBASE_HOME/lib/commons-httpclient-3.1.jar:$HBASE_HOME/lib/jetty-6.1.24.jar:$CLASSPATH
export CLASSPATH=$HBASE_HOME/lib/jetty-util-6.1.24.jar:$HBASE_HOME/lib/hadoop-core-0.20.3-append-r964955-1240.jar:$CLASSPATH
export CLASSPATH=$HBASE_HOME/lib/hbase-0.89.20100924.jar:$HBASE_HOME/lib/hsqldb-1.8.0.10.jar:$CLASSPATH
12) Run HBase demo:
jongwook@ip-10-xx-xx-xx:/usr/local$ cd hbase-0.89.20100924/
jongwook@ip-10-xx-xx-xx:/usr/local/hbase-0.89.20100924$ ls
bin CHANGES.txt conf docs hbase-0.89.20100924.jar hbase-webapps lib LICENSE.txt NOTICE.txt README.txt
jongwook@ip-10-108-155-6:/usr/local/hbase-0.89.20100924$ bin/hbase shell
HBase Shell; enter 'help
' for list of supported commands.
Type "exit" to leave the HBase Shell
Version: 0.89.20100924, r1001068, Tue Oct 5 12:12:44 PDT 2010
hbase(main):001:0> status 'simple'
5 live servers
ip-10-71-70-182.ec2.internal:60020 1308520337148
requests=0, regions=1, usedHeap=158, maxHeap=1974
domU-12-31-39-0F-B5-21.compute-1.internal:60020 1308520337138
requests=0, regions=0, usedHeap=104, maxHeap=1974
domU-12-31-39-0B-90-11.compute-1.internal:60020 1308520336780
requests=0, regions=0, usedHeap=104, maxHeap=1974
domU-12-31-39-0B-C1-91.compute-1.internal:60020 1308520336747
requests=0, regions=1, usedHeap=158, maxHeap=1974
ip-10-108-250-193.ec2.internal:60020 1308520336863
requests=0, regions=0, usedHeap=102, maxHeap=1974
0 dead servers
Aggregate load: 0, regions: 2